

Overview
As we all know that Elasticsearch is a search engine built on Apache Lucene and it is a full-text search and open-source analytics engine which is highly scalable, let us discuss some of the important and unknown things about Elasticsearch.
We can also say Elasticsearch is a database that allows us to store, search, and analyze complex data volumes faster in near real-time. On top of Lucene Standard Analyzer, Elasticsearch provides a distributed system for indexing and automatic type guessing utilizing a JSON based REST API (because Elasticsearch is developed in Java) referring to Lucene features.
According to DB-Engines ranking, Elasticsearch is a popular search engine followed by Apache Solr, which is also based on Lucene.
Introduction
As Elasticsearch hides complexity from beginners, it is also easy to set up out of the box since it ships with sensible defaults. With minimal efforts being invested in it, one can grasp the basics easily with its short learning curve and become productive shortly. It’s schema-less based, using some defaults for data indexing.
Backend components of Elasticsearch
Because it’s good to have a basic understanding of the main backend components, few of them are listed below.
Noda
Node is a single server, a part of a cluster that stores our data, participates in cluster’s indexing and search capabilities, and can be identified by name, same as a cluster. By default, it is a random Universally Unique Identifier (UUID) assigned at startup, which is editable.
Cluster
Holding our data together and providing federated indexing and search capabilities with more than one node collection is denoted as a cluster. There can be N nodes with the same cluster name.
Elasticsearch operates in a distributed cross-cluster replication system, so a secondary cluster may serve as a hot backup.
Index
As a collection of documents with identical features, for suppose, we can have an index for a specific customer, one for product info identified by a unique name to retrieve when performing indexing search, update/delete operations. An index is similar to a database in RDBMS, where we can define as many indexes in a single cluster.
Document
A document is a basic information unit that can be indexed. For instance, you can have an index about a product and a corresponding document for each customer expressed in JSON format. Multiple documents can be shared for one single product.
Shards and Replicas
Shard is a subset of index documents where an index can be divided into many shards. A shard can host on any node in the cluster since it’s a fully-functional and independent index.
What’s so Significant about Elasticsearch?
ES is purely a document-oriented database designed to store, retrieve, and manage either document-oriented or semi-structured data. While using ES, we store the data in JSON format, and we query them for retrieval.
Because ES uses Lucene Standard Analyzer for indexing automatic type guessing, every feature of ES is exposed as a REST API as:
- Index API used to document the index,
- Get API used to retrieve the document,
- Search API used to submit the query and get a result
- Put Mapping API used to override the default choices and define the mapping.
We can nest any queries as we need because the real-world projects require different search conditions like weights, predefined field values, and so on.
Such complexities can be expressed through a single DSL query, powerful and designed to handle real-world query complexity, which also uses the Lucene TermQuery to execute.
How does ES work?
Internally, ES works on “sharing nothing” architecture, where the primary ES data structure uses the inverted index managed using Lucene’s APIs.
In simple terms, an inverted index is a mapping of each unique ‘word’ (token) to documents (locations) list containing that word, which makes it possible to locate documents with provided keywords quickly.
Index information stored in one or multiple partitions called Shards and ES is able to distribute and allocate shards dynamically to the nodes in a cluster, and replicate them.
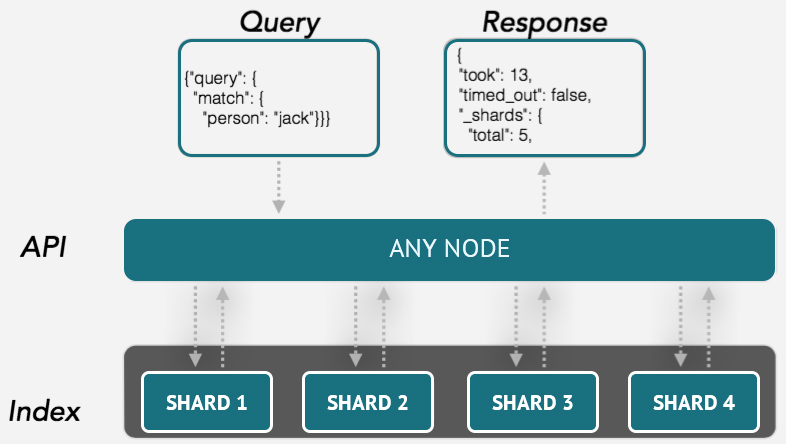
This mechanism makes it flexible concerning the data distribution, and redundancy can be provided by distributing that replica shards (primary shard ‘copies’) to different cluster nodes. Indexing operations use primary shards, and search queries use both shard types.
With multiple nodes and replicas increases query performance.
ES use cases
While ES can be used in various ways, one of the use cases is listed below because it is difficult to capture all.
- Cisco Commerce delivery platform
Cisco upgraded its commercial platform to ES when it was introduced in 2017, switching from RDBMS for the reasons:
- RDBMS is not distributed and fault-tolerant.
- Type-ahead and Rank-based search for data sourced from multiple Databases on 30/40 attribute to get sub-second responses.
- Global Search – If no specific objects are specified in the search, the search engine will find results against multiple objects.
- Instant search on E-commerce platform across Retail Product Catalogues
Many retailers like Amazon, Flipkart, and BigBasket use ES to index their product catalogs and inventory, alongside all the product attributes. So, when the buyer searches for a specific product attribute, the store can display the right products instantly, including features/specs.
A near-instant search bar will up the revenue by delivering a better product catalog search experience for the user and make the search a primary navigation form.
Walgreens and Kreeger are also the biggest retail companies streamlining their online grocery shopping experience with Elasticsearch.
Compatibility
ES has a rich set of client libraries for many programming languages like Java, JS, PHP, C#, Python, Go, and many more. By this, the user can integrate with ES quite easily.
Benefits of using ES
Fast-Time-to-Value
ES offers simple REST APIs, which is an HTTP interface and uses schema-free JSON documents for quick building applications for a variety of use-cases.
Near Real-Time operations
Usually, ES operations like Reading/Writing data takes less than a second to complete. This lets us use ES for near Real-Time use-cases like anomaly detection and application monitoring.
Complimentary Tools and Plugins
ES comes integrated with Kibana, one of the popular visualization and reporting tool. In addition, ES offers integration with Beats and Logstash, enabling you to transform source data and load it to your ES cluster.
Bottlenecks
Few of ES’s bottlenecks include:
- ES doesn’t support multi-language in terms of handling request and response data (other than JSON), unlike in Apache Solr (also supports CSV, XML).
- ES is not good at data stores like MongoDB, Hadoop. Even if it worked fine for smaller use cases, streaming TerraBytes of data might occur in chokes or losses of data.
Conclusion
Being ES is a distributed, RESTful, and analytics search engine capable of solving a wide variety of problems, many companies are switching to ES and integrating with their current backend infrastructure since:
- Tools like Kibana and Logstash allow you to make sense of your data in such simple and quick ways by using charts and performing the granular searches.
- ES allows you to zoom out to your data using aggregation and make sense of billions of log lines.
- It combines different types of searches like structured, unstructured, geo, application search, security analytics, metrics, and logging.
We, at ScriptBees, with our dedicated resource team, we’ll provide you with a well equipped and customized search engine built on Apache Lucene, meeting all the standard requirements proposed by the user/client. However, further support will also be provided for the scalability and necessary changes that are needed.